Statistische Methoden im Qualitätsmanagement
(1) Statistische Grundlagen
In der Fertigungstechnik und in der Realität gibt es keine exakten Nominalwerte (Sollwewerte). Wenn Bauteile in Serie produziert werden, weichen sie aufgrund von unvorhersehbaren Umgebungseinflüssen und dem Zufall immer minimal von ihrem theoretischen Sollwert ab. Da man es in der Praxis folglich stets mit unscharfen Größen zu tun hat, sind statistische Regeln für den Umgang mit diesen Abweichungen zwingend erforderlich. Zum Einsatz kommen diese Regeln unter anderem bei:
- Festlegung von Toleranzen,
- Beurteilung von Fertigungsprozessen,
- Optimierung von Fertigungsprozessen,
- Abschätzung der Funktionsfähigkeit von Entwicklungen,
- Lebensdauerabschätzung und Festlegung von Wartungsintervallen.
Der Mensch ist von Natur aus extrem gut darin, bestimmte Muster zu erkennen und zu bewerten. Genau dieses Prinzip der Mustererkennung wird in der Statistik angewendet: Es kommt weniger auf die numerische Größe einzelner Messwerte an, sondern vielmehr auf das spezifische Muster, das eine Vielzahl von Messwerten im zeitlichen Verlauf bildet.
Für das Beschreiben und Beurteilen dieser Muster im Qualitätswesen reichen wenige Größen aus. Zunächst betrachtet man die Lage der Werte. Eine wichtige Kennzahl hierfür ist der Median, der den mittleren Wert einer der Größe nach geordneten Reihe darstellt und unempfindlich gegenüber Ausreißern ist.
Die Formel zur Berechnung des Medians lautet:

Bei einer ungeraden Anzahl liegt der Median also exakt in der Mitte der sortierten Reihe, bei einer geraden Anzahl wird er aus dem Durchschnitt der beiden mittleren Werte gebildet.
Eine weitere statistische Größe für die Lage ist der empirische Mittelwert, der den klassischen Durchschnitt einer Stichprobe beschreibt. Die Formel lautet:

Hierbei werden alle n Einzelwerte (xi) der Stichprobe aufsummiert und anschließend durch die Anzahl n geteilt. Möchte man stattdessen den wahren Mittelwert μ berechnen, wendet man dieselbe Logik auf die gesamte Grundgesamtheit m (beispielsweise die komplette Tagesproduktion) an. Die Formel lautet dann analog:

Neben der Lage ist die Streuung entscheidend, da sie ausdrückt, wie weit die einzelnen Werte um den Mittelpunkt variieren. Eine einfache Kennzahl hierfür ist die Spannweite (Range s), welche den bloßen Abstand zwischen dem größten und dem kleinsten Wert misst. Da die einfache Summe der Abstände zum Mittelwert null ergeben würde (weil sich positive und negative Abstände exakt aufheben), nutzt man den mittleren quadratischen Abstand. Dabei werden die Abstände zum Mittelwert quadriert, weshalb diese Streuung als

dargestellt wird.
In der Praxis wird allerdings sehr häufig die Varianz σ² als beschreibende Größe für die Streuung verwendet. Die Berechnung der Varianz erfolgt über die Formel
 .
.
Im Gegensatz zum mittleren quadratischen Abstand wird die Quadratsumme hier durch (n-1) geteilt. Zieht man aus der Varianz die Wurzel, erhält man die Standardabweichung s, welche bei der Normalverteilung den horizontalen geometrischen Abstand des Wendepunktes von der Mittelachse beschreibt. Spricht man von einer empirischen Standardabweichung s, so bedeutet dies, dass die Berechnung lediglich auf Basis eines Ausschnitts (einer Stichprobe) und nicht der kompletten Grundgesamtheit durchgeführt wurde. Für schnellere Berechnungen im Qualitätswesen, bei denen man nicht in einem Zwischenschritt vorab den Mittelwert berechnen möchte, nutzt man oft die mathematisch umgeformte Variante der Varianz:

Um die derart ermittelten Wertmuster aus der Fertigung abschließend beurteilen zu können, werden sie mit bekannten Referenzmustern wie Wahrscheinlichkeits-, Verteilungs- und Dichtefunktionen verglichen. Hierfür benötigt man grundlegende Kenntnisse der Wahrscheinlichkeitsrechnung.
Man unterscheidet zunächst zwischen der absoluten Häufigkeit, die zählt, wie oft ein Ereignis konkret aufgetreten ist, und der relativen Häufigkeit, bei der die absolute Häufigkeit ins Verhältnis zur Anzahl aller Versuche gesetzt wird. Führt man einen Versuch gedanklich unendlich oft weiter, nähert sich die relative Häufigkeit als Asymptote einem festen Wert an, der als Wahrscheinlichkeit bezeichnet wird.
Für das Rechnen mit Wahrscheinlichkeiten gelten zwei wesentliche Regeln.
Der Additionssatz besagt, dass sich die Einzelwahrscheinlichkeiten von Ereignissen addieren, wenn entweder Ereignis A oder Ereignis B eintreten soll. Voraussetzung hierfür ist, dass sich die Ereignisse gegenseitig ausschließen und unabhängig voneinander sind.
Der Multiplikationssatz kommt hingegen zur Anwendung, wenn verschiedene unabhängige Ereignisse nacheinander eintreten sollen, also beispielsweise erst Ereignis A und danach Ereignis B. In diesem Fall werden die Einzelwahrscheinlichkeiten miteinander multipliziert. Bei kleineren Problemstellungen lassen sich diese Wahrscheinlichkeiten am einfachsten grafisch mit Hilfe eines Baumdiagramms veranschaulichen und berechnen.
Hier ist die Zusammenfassung für Kapitel 2: Datensammlung im Qualitätswesen. In diesem Kapitel geht es darum, warum und wie Daten erhoben werden, um Prozesse zu steuern, statt sie nur passiv zu archivieren.
(2) Datensammlung im Qualitätswesen
Das Sammeln von Mess- und Qualitätsdaten für ein Produkt stellt an sich in der Regel keine direkte Wertschöpfung dar. Die Daten werden primär erhoben, um Fertigungsprozesse nach deren Auswertung fundiert bewerten und steuern zu können. Ein weiterer wesentlicher Grund für die Datenerfassung ist die Beweissicherung gegenüber Haftungsforderungen (z. B. Produkthaftung), um sich gegen Ansprüche wegen angeblich fehlerhafter Teile abzusichern.
In der Praxis werden Messdaten aus der Vergangenheit leider viel zu selten bereits in der Entwicklungsphase neuer Produkte für die Festlegung von Toleranzen genutzt. Dabei hätte die Entwicklung oft die Chance, Produkte so zu gestalten, dass notwendige Toleranzen in unkritischen Bereichen liegen. Grundsätzlich sollten sich Toleranzen an den natürlich auftretenden Streuungen der Produktion orientieren, da es immer sehr kostenintensiv ist, diese natürlichen Streuungen nachträglich reduzieren zu wollen.
Häufig werden Mess-, Qualitäts- und Fertigungsdaten heute lediglich aufgezeichnet und abgelegt, ohne sie weiter zu nutzen. Dabei bieten diese Daten die wertvolle Möglichkeit, zu aussagekräftigen Mustern aufbereitet zu werden. Mithilfe grundlegender statistischer Kenntnisse können diese Muster wichtigen Aufschluss über den Zustand der Fertigung geben und somit als Informationsquelle für die kontinuierliche Produktentwicklung dienen.
(3) Verteilungen und Vertrauensbereiche
Auf jeden Fertigungsprozess wirken äußere Einflüsse ein, die sowohl systematischer als auch zufälliger Natur sein können. Um einen Prozess oder dessen Ergebnisse beurteilen zu können, reicht meist eine einzelne Betrachtung nicht aus, da man die Art und Größe der entstehenden Unschärfe ermitteln muss. Dies wird anhand von Beispielen, wie der Prüfung von Schweißpunkten im Fahrzeugrohbau oder dem Ziehen farbiger Kugeln aus einer Box, verdeutlicht. Es zeigt sich, dass eine einzige, kleine Stichprobe keine sichere Aussage über die tatsächliche Zusammensetzung der gesamten Grundmenge zulässt, da die Ergebnisse von Ziehung zu Ziehung stark variieren.
Eine deutliche Vergrößerung des Stichprobenumfangs würde zwar die Variation verringern und die Genauigkeit der Aussage erhöhen, ist jedoch in der Praxis aus Kosten- und Zeitgründen meist nicht praktikabel. Aus diesem Grund nutzt die Statistik das Prinzip der Musterbewertung. Führt man Stichprobenziehungen unter gleichen Bedingungen sehr häufig durch, nehmen die daraus resultierenden Häufigkeitsverteilungen irgendwann eine stabile, typische Form an. Diese stabilen Ausprägungen lassen sich in der Technik in wenige typische Klassen einteilen und durch einzelne charakteristische Größen mathematisch beschreiben und berechnen.
Das Wissen um diese typischen Muster ermöglicht es Ingenieuren, das Ergebnis einer kleinen Stichprobe mit den bekannten Referenzmustern zu vergleichen. Gelingt diese Musteridentifikation, lässt sich ableiten, in welchem Bereich sich die echte Zusammensetzung der Grundgesamtheit mit einer bestimmten, hohen Sicherheit befindet. Dieser Bereich wird als Vertrauensbereich bezeichnet. Besonders hilfreich ist in der Praxis die Tatsache, dass das Auftreten der unterschiedlichen Verteilungstypen an ganz spezifische Randbedingungen geknüpft ist. Erkennt man diese Randbedingungen, kann man bereits vorab eine fundierte Aussage über die zu erwartende Form der Häufigkeitsverteilung treffen und die entsprechenden statistischen Schlussfolgerungen für den Vertrauensbereich ziehen.
Hier ist die Zusammenfassung für das Kapitel 4.1 (Hypergeometrische Verteilung). Wie besprochen verzichte ich komplett auf Zitier-Formatierungen und halte mich streng an einen reinen Fließtext, da auch im Original an dieser Stelle keine Aufzählungen verwendet werden:
(4) Wichtige Verteilungsformen und deren Regelkarten
(4.1) Hypergeometrische Verteilung
Die hypergeometrische Verteilung ist eine typische Methode für Ingenieure, um den Anteil fehlerhafter Einheiten in einer Lieferung oder Produktion anhand von Stichproben zu beurteilen. Die grundlegende Problemstellung sieht so aus: Es gibt eine begrenzte Grundgesamtheit von N Einheiten, in der sich d fehlerhafte und somit N-d fehlerfreie Teile befinden. Aus dieser Menge wird eine Stichprobe vom Umfang n gezogen, wobei jedes Teil die exakt gleiche Chance haben muss, in die Stichprobe zu gelangen. Gesucht wird die Wahrscheinlichkeit, dass sich in der Stichprobe genau x fehlerhafte Einheiten befinden. Diese Zahl x ist eine Zufallsgröße und kann maximal so groß sein wie d.
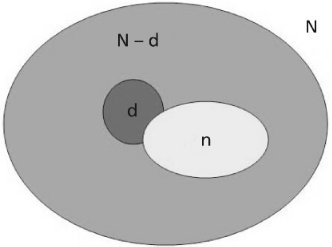
Das absolute Hauptmerkmal und die zwingende Voraussetzung für die hypergeometrische Verteilung ist die begrenzte Grundgesamtheit. Wenn man ein Teil zieht, reduziert sich die verbleibende Menge um eins, wodurch sich die Ziehwahrscheinlichkeit für jedes nachfolgende Teil merklich verändert. Das erste Teil hat beispielsweise die Wahrscheinlichkeit 1 / N, gezogen zu werden, das zweite Teil dann schon 1/(N-1). Ein klassisches Beispiel für dieses Prinzip der sich ständig verändernden Wahrscheinlichkeiten ist das bekannte Lotto-Spiel (6 aus 49).
Um die Wahrscheinlichkeit für das Eintreten bestimmter Kombinationen berechnen zu können, nutzt man in der Mathematik den Binomialkoeffizienten, geschrieben als ![]() (gesprochen: "N über x"). Er gibt an, wie viele nicht wiederkehrende Kombinationen von
(gesprochen: "N über x"). Er gibt an, wie viele nicht wiederkehrende Kombinationen von x Elementen aus einer Menge von N Elementen gebildet werden können. Berechnet wird dieser über Fakultäten (das Ausrufezeichen) mit der Formel
![]()
Mit diesem Werkzeug der Kombinatorik lässt sich die hypergeometrische Wahrscheinlichkeitsfunktion g(x) aufstellen. Sie berechnet sich, indem man die Kombinationsmöglichkeiten für die fehlerhaften Teile mit den Kombinationsmöglichkeiten für die fehlerfreien Teile multipliziert und das Ergebnis durch die Anzahl aller überhaupt möglichen Kombinationen teilt. Die mathematische Formel lautet dementsprechend:

Dabei beschreibt g(x) die Wahrscheinlichkeitsfunktion (also die Höhe der einzelnen Balken im Diagramm), während man bei der Aufsummierung dieser Einzelwahrscheinlichkeiten von der Verteilungsfunktion G(x) spricht.
Zusammenfassend lässt sich sagen, dass die hypergeometrische Verteilung ausschließlich für diskrete Merkmale gilt, bei denen es nur ein klares Entweder-Oder gibt (wie gut oder schlecht, schwarz oder weiß). Die Form der Verteilung ist dabei immer unsymmetrisch und hängt ausschließlich von der Größe der Grundgesamtheit N, dem Stichprobenumfang n und der Anzahl der tatsächlichen Merkmalsträger d ab. Wichtig ist zudem für die praktische Anwendung, dass das statistische Prinzip nur funktioniert, wenn jedes Teil zum Zeitpunkt der Ziehung auch wirklich die gleiche Wahrscheinlichkeit hat, gegriffen zu werden. Liegen beispielsweise in einer Transportbox bestimmte Teile aufgrund ihrer Form immer oben und werden deshalb von den Prüfern häufiger gegriffen, liefert die hypergeometrische Musterberechnung ein falsches Ergebnis.
Da hast du völlig recht, entschuldige bitte! Ich bin da im Eifer des Gefechts zu sehrs im "Fließtext-Modus" geblieben und habe dir unsere schöne und übersichtliche Struktur unterschlagen. Auch die Formel gehört hier natürlich unbedingt rein!
Lass uns das Kapitel 4.2 direkt vernünftig, übersichtlich und mit der dazugehörigen Mathematik strukturieren.
(4.2) Binomialverteilung
Die Binomialverteilung ist die "große Schwester" der hypergeometrischen Verteilung. Sie kommt immer dann zum Einsatz, wenn die Kiste (Grundgesamtheit N) im Vergleich zur Stichprobe (n) riesengroß oder unendlich ist (z. B. bei einer laufenden Fließbandproduktion).
Als Faustregel gilt: Wenn N / n > 15 ist, greift man zur Binomialverteilung. Weil die Kiste so riesig ist, verändert sich die Wahrscheinlichkeit bei der Entnahme einzelner Teile praktisch nicht mehr. Die Fehlerwahrscheinlichkeit bleibt immer konstant.
Die Formel der Binomialverteilung
Auch hier geht es um die Frage: Wie wahrscheinlich ist es, genau x fehlerhafte Teile in meiner Stichprobe zu finden?

Was bedeuten die Variablen in dieser Formel?
n(Stichprobenumfang): Wie viele Teile ziehst du insgesamt?x(Anzahl der Fehler): Wie viele kaputte Teile suchst/erwartest du in der Stichprobe?p(Fehlerwahrscheinlichkeit): Wie hoch ist die generelle Fehlerquote der Maschine? (z. B. 0,05 für 5 %).(1-p)Das ist die Wahrscheinlichkeit, dass ein Teil heil ist (Gegenwahrscheinlichkeit). der Binomialkoeffizient: Er berechnet, wie viele verschiedene Reihenfolgen es gibt, diese
der Binomialkoeffizient: Er berechnet, wie viele verschiedene Reihenfolgen es gibt, diese xkaputten Teile aus denngezogenen Teilen herauszugreifen.
(In einfachen Worten: Die Formel multipliziert die Wahrscheinlichkeit für die kaputten Teile mit der Wahrscheinlichkeit für die heilen Teile und mischt das Ganze mit der Anzahl der möglichen Kombinationen.)
(4.2.1) Grundlagen der Binomialverteilung
Diese Verteilung gilt ausschließlich für diskrete Entweder-Oder-Merkmale (z. B. "Teil ist gut" oder "Teil ist Ausschuss").
- Symmetrie: Die Verteilung ist meistens schief (asymmetrisch). Sie wird nur dann perfekt symmetrisch (wie eine Glocke), wenn die Fehlerwahrscheinlichkeit bei exakt $p = 0,5$ (50 %) liegt oder die Stichprobe sehr groß wird.
- Das Larson-Nomogramm: Weil das ständige Aufsummieren dieser Formel (für das große $G(x)$) per Hand ewig dauert, gibt es im Skript ein grafisches Werkzeug: das Larson-Nomogramm. Damit kann man Wahrscheinlichkeiten, Stichprobengrößen und Fehlermengen einfach mit einem Lineal ablesen, statt sie mühsam zu rechnen.
(4.2.2) Anwendung der Binomialverteilung bei Qualitätsregelkarten
Hier wird die Statistik zum echten Werkzeug für die Produktion. Man nutzt die Binomialverteilung, um Qualitätsregelkarten (QRK) für die laufende Fertigung zu erstellen.
- Zufall vs. Störung: Jede Maschine hat kleine, natürliche Schwankungen. Mit der Binomialverteilung berechnet man Grenzlinien (Eingriffsgrenzen). Solange die Fehlerquote innerhalb dieser Grenzen bleibt, ist alles nur Zufall.
- Alarmsignale: Bricht ein Wert aus diesen Grenzen aus, muss der Ingenieur die Maschine stoppen.
- Mustererkennung (Runs & Trends): Selbst wenn die Grenzen nicht überschritten werden, schlägt man Alarm, wenn unnatürliche Muster auftreten. Ein Run sind z. B. 7 Messwerte in Folge oberhalb der Mittellinie. Ein Trend sind 7 Werte, die stetig ansteigen. Beides ist mathematisch so unwahrscheinlich, dass ein echter Maschinenfehler vorliegen muss.
(4.2.3) Abschätzung des Anteils fehlerhafter Einheiten
In der Realität kennt man die exakte Fehlerquote (``p`) der Gesamtproduktion oft gar nicht, sondern hat nur das Ergebnis einer winzigen Stichprobe.
- Die Schätzung: Man nutzt die Stichprobe, um auf die gesamte Produktion zu schließen. Da aber viel Zufall im Spiel ist, reicht ein einzelner Prozentwert als Schätzung nicht aus.
- Der Vertrauensbereich (Konfidenzintervall): Man berechnet (oft wieder rückwärts über das Larson-Nomogramm) eine Unter- und eine Obergrenze. Das Ergebnis lautet dann nicht: "Die Maschine produziert 3 % Ausschuss", sondern seriöser: "Mit 95 %iger Sicherheit liegt der wahre Ausschussanteil der Maschine irgendwo zwischen 1 % und 6 %."
Hier ist die Zusammenfassung für das komplette Kapitel 4.3 zur POISSONverteilung. Das Gute vorweg: Für den Taschenrechner wird es jetzt im Vergleich zur Binomialverteilung sogar ein bisschen entspannter!
(4.3) POISSONverteilung
Die Poissonverteilung (oft auch "Verteilung der seltenen Ereignisse" genannt) kommt im Qualitätsmanagement immer dann zum Einsatz, wenn eine riesige Fläche, Menge oder Zeitspanne betrachtet wird, auf der theoretisch unendlich viele Fehler passieren könnten, die Wahrscheinlichkeit für einen Fehler an einer ganz bestimmten Stelle aber extrem winzig ist.
Typische Beispiele aus der Praxis:
- Die Anzahl der Kratzer auf einer großen Autotür.
- Die Anzahl der Webfehler auf einer 100 Meter langen Stoffrolle.
- Die Anzahl der Lufteinschlüsse in einer großen Glasscheibe.
Bei der Binomialverteilung zählt man defekte Teile (entweder ganz oder kaputt). Bei der Poissonverteilung zählt man Fehler pro Einheit (ein einziges Teil kann beispielsweise 5 Kratzer haben).
Die Formel der Poissonverteilung

x: Die gesuchte Anzahl der Fehler (z. B. "Wie wahrscheinlich sind genau 2 Kratzer?").λ(Lambda): Diese Wert steht für die durchschnittliche Fehlerzahl, die man aus Erfahrung kennt. Wenn im Schnitt 3 Kratzer pro Autotür vorkommen, istλ=3. Manchmal wird Lambda auch berechnet ausn * p.e: Das ist die Eulersche Zahl, eine feste mathematische Konstante (ca. 2,718).x!: Die Fakultät vonx
(4.3.1) Grundlagen der POISSONverteilung
Die Poissonverteilung wird oft genutzt, um die Binomialverteilung abzukürzen. Wenn die Stichprobe n sehr groß ist (größer als 50) und die Fehlerwahrscheinlichkeit p sehr klein ist (kleiner als 10 %, also 0,1), würde der Binomialkoeffizient den Taschenrechner sprengen. In diesem Fall liefert die einfache Poisson-Formel fast exakt dasselbe Ergebnis wie die Binomial-Formel.
Das Besondere an der Poissonverteilung ist, dass sie komplett über diesen einen einzigen Wert λ (den Durchschnitt) gesteuert wird. Weder N noch n müssen daher bekannt sein.
(4.3.2) Anwendung bei Qualitätsregelkarten (Fehlersammelkarten)
Weil es hier nicht um "Ausschuss ja/nein" geht, sondern um das Zählen von Fehlern auf einem Bauteil, nutzt man die Poissonverteilung für spezielle Regelkarten (oft c-Karten oder u-Karten genannt).
- Der Mittelwert ist Lambda: Die Mittellinie auf der Regelkarte ist einfach der erfahrungsgemäße Durchschnitt
λ. - Eingriffsgrenzen berechnen: Mit der Formel rechnet man aus, ab wie vielen Fehlern pro Teil (z. B. ab 7 Kratzern) der Zufall aufhört und ein echtes Maschinenproblem beginnt. Zieht ein Prüfer dann ein Teil mit 8 Kratzern, schlägt das System Alarm.
(4.3.3) Vertrauensbereiche
Wie schon bei der Binomialverteilung gilt auch hier: Wenn man nur eine einzige Stoffrolle auf Webfehler untersucht wird und dort 4 Fehler gefunden werden, heißt das nicht, dass die gesamte Tagesproduktion im Schnitt exakt 4 Fehler pro Rolle hat.
- Auch hier baut man sich mit der Statistik einen "Puffer" auf und berechnet einen Vertrauensbereich.
- Das Ergebnis ist dann eine Aussage wie: "Basierend auf unseren 4 gefundenen Fehlern können wir mit 95 %iger Sicherheit sagen, dass der wahre Durchschnitt (
λ) der gesamten Produktion irgendwo zwischen 1,5 und 8,2 Fehlern pro Rolle liegt."
(4.4) Normalverteilung
Die Normalverteilung (Gauß-Verteilung) findet Anwendung bei der Auswertung von kontinuierlichen, messbaren Merkmalen (z. B. Länge, Gewicht, Temperatur). Sie beschreibt die symmetrische Streuung von Messwerten um einen zentralen Erwartungswert in Form einer Glockenkurve.
Dichtefunktion der Normalverteilung
Die mathematische Beschreibung der Kurve erfolgt über die Dichtefunktion:

μ: Der wahre Mittelwert (Erwartungswert) der Grundgesamtheit. Er definiert die Lage des Maximums der Kurve.σ(Sigma): Die Standardabweichung der Grundgesamtheit. Sie definiert die Breite (Streuung) der Kurve.
(4.4.1) Grundlagen und Standardnormalverteilung
Da es für jede Kombination aus μ` und σ`` eine eigene Normalverteilung gibt, wird in der Praxis die sogenannte Standardnormalverteilung herangezogen. Dies geschieht über die z-Transformation.
Hierbei wird ein beliebiger Messwert x in einen dimensionslosen z-Wert überführt, der angibt, um wie viele Standardabweichungen der Wert vom Mittelwert entfernt liegt:
![]()
Mithilfe des berechneten z-Wertes lassen sich die zugehörigen Wahrscheinlichkeiten direkt aus der Tabelle der Standardnormalverteilung ablesen.
Zudem gelten für die Normalverteilung feste Streuungsintervalle:
- Im Bereich
μ` +- 1σ`` liegen ca. 68,27 % aller Werte. - Im Bereich
μ` +- 2σ`` liegen ca. 95,45 % aller Werte. - Im Bereich
μ` +- 3σ`` liegen ca. 99,73 % aller Werte.
(5) Stichprobenanweisungen und Operationscharakteristik
Die Auslegung einer Stichprobenanweisung basiert auf der Vereinbarung zwischen Lieferant und Abnehmer über eine bestimmte Fertigungsqualität p (Anteil schlechter Teile) und die Wahrscheinlichkeit, mit der diese Qualität bei einer Prüfung angenommen wird (Annahmewahrscheinlichkeit Pa).
Ein Restrisiko der Fehlentscheidung verbleibt bei jeder Stichprobe:
- Lieferantenrisiko (
α): Die Wahrscheinlichkeit, dass eine Lieferung zurückgewiesen wird, obwohl die vereinbarte Fertigungsqualität eingehalten wurde. Die Annahmewahrscheinlichkeit berechnet sich ausPa = 1 - α. - Abnehmerrisiko / Kundenrisiko (
ß): Die Wahrscheinlichkeit, dass eine Lieferung angenommen wird, obwohl die tatsächliche Fertigungsqualität unzureichend ist (Qualitätsgrenzlagepß).
Zur Ermittlung einer passenden Kombination aus Stichprobenumfang n und Annahmezahl c kann das LARSON-Nomogramm genutzt werden.
Die Operationscharakteristik
Die Operationscharakteristik visualisiert die Annahmewahrscheinlichkeit Pa in Abhängigkeit der Fertigungsqualität p. Eine ideale Operationscharakteristik (100 % Annahme bis zum Grenzwert, danach 0 % Annahme) ist in der Praxis nur durch eine 100-%-Prüfung realisierbar.
Für Stichproben wird die Operationscharakteristik über die Verteilungsfunktion der Binomialverteilung berechnet:
![]()
Ein zunehmender Stichprobenumfang n nähert die Kurve der idealen Operationscharakteristik an, erhöht jedoch den Prüfaufwand.
Der Durchschlupf (D)
Trotz Stichprobenprüfung gelangt ein gewisser Anteil fehlerhafter Teile zum Abnehmer. Dieser sogenannte Durchschlupf berechnet sich in der Praxis ausgedrückt durch:
D = p \cdot P_a
Da bei der eigentlichen Prüfung gefundene Fehlteile aussortiert werden, lautet die exakte mathematische Korrektur:
D = p \cdot P_a \cdot \left(1 - \frac{n}{N}\right)
Der maximale Durchschlupf steigt zunächst proportional zur Verschlechterung der Fertigungsqualität an. Ab einem bestimmten Punkt sinkt er jedoch wieder, da die Wahrscheinlichkeit einer kompletten Los-Rückweisung bei sehr schlechter Qualität massiv ansteigt.
(7.2) Mehrfachstichproben
Mehrfachstichproben dienen der Reduktion des Zeit- und Kostenaufwands gegenüber Einfachstichprobenanweisungen. Durch eine stufenweise Prüfung kann bei extrem guter oder extrem schlechter Qualität frühzeitig eine Entscheidung getroffen werden, wodurch sich der durchschnittliche Prüfaufwand verringert.
Die gängigste Form ist die Doppelstichprobenanweisung. Ihre standardisierte Notation lautet:
(n - c_1) / (d_1 - c_{1+2})
n: Stichprobenumfang pro Ziehungc_1: Annahmezahl für den 1. Teil der Stichprobenprüfungd_1: Rückweisungszahl für den 1. Teil der Stichprobenprüfungc_{1+2}: Annahmezahl für den 1. und 2. Teil der Stichprobenprüfung (in Summe)
Ablauf der Entscheidungsfindung:
- Es wird eine erste Stichprobe vom Umfang $n$ gezogen und geprüft.
- Ist die Anzahl der fehlerhaften Einheiten $\le c_1$, wird die Lieferung sofort angenommen.
- Ist die Anzahl der fehlerhaften Einheiten $\ge d_1$, wird die Lieferung sofort zurückgewiesen.
- Liegt die Fehleranzahl zwischen $c_1$ und $d_1$ (exklusiv), ist keine Sofortentscheidung möglich. Es muss zwingend eine zweite Stichprobe vom Umfang $n$ gezogen werden.
- Die Fehlerzahlen beider Stichproben (Gesamtumfang $2n$) werden addiert. Ist die Summe $\le c_3$, erfolgt die Annahme. Ist die Summe größer, erfolgt die Rückweisung.
Anwendungsbeispiel ($80 - 2 / 5 - 6$): Im ersten Schritt werden 80 Teile entnommen. Bei 0 bis 2 Fehlern erfolgt die Annahme, bei $\ge$ 5 Fehlern die Rückweisung. Werden 3 oder 4 Fehler gefunden, werden weitere 80 Teile gezogen. Die Gesamtlieferung wird dann angenommen, wenn in den insgesamt 160 geprüften Teilen maximal 6 fehlerhafte Einheiten enthalten sind.